CNN 의 기본 Architecure인 Conv-Pool-Conv-Pool-FC-FC를 따르면서 사이사이에 LRN(Local Response Nomalization)이라는 정규화를 넣은 AlexNet에 대한 논문리뷰를 진행하겠습니다.
논문에 사용된 기법등 하나하나가 딥러닝에서 많이 사용되는것이기 때문에 각각을 따로 공부하는것도 매우 도움이 됩니다. ( Drop out , Pooling , Normalization ,Weight decay 등등)
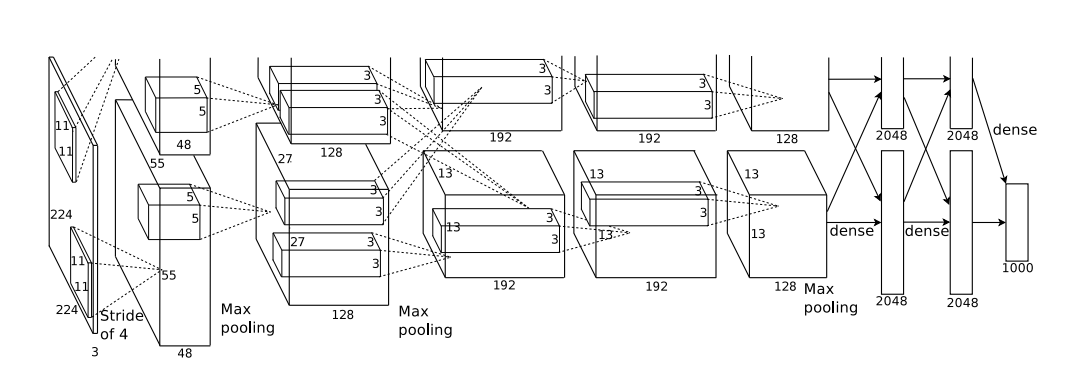
Alexnet의 특징
1. Activation function 으로 ReLU사용.
이 논문이 나오던 당시에는 Activation function으로 tanh 나 sigmoid 함수를 많이 사용하였는데 , ReLU를 사용함으로써 좀더 빠르고 error rate가 낮음에 대해 설명하였습니다.
2. 병렬 GPU 사용
120만개의 이미지를 학습해야하는데 , 당시(2012년)의 학습에 사용된 GPU는 GTX580 3GB로 메모리가 많이 부족하였니다. 그래서 2개의 GPU를 통해 병렬로 학습을 하여 메모리의 한계를 극복하려 노력하였습니다.
예를 들어 128개의 Convolution filter를 64개 / 64개로 나누거나 , 96개의 Convoulution filter를 48개/ 48개로 나누어 학습하였습니다.
추가적인 Trick으로 일반적으로 Kenel은 바로 앞전의 Layer 정보를 Input으로 받지만 , 아래와 같이 GPU 2를 병렬로 사용하여 , 바로 전단의 layer가 아닌 Cross로 정보를 받을수 있습니다.

3. Local Response Normalization ( LRN ) 사용
Batch normalizaton 의 시초라 할수 있고 ReLU를 쓸경우 Activation function 이 Saturated 부분이 없지만 그 값이 무한히 커질 가능성이 있어 너무 큰 값이 주변 값들을 무시할 수도 있습니다.
실제 뇌세포의 증상으로 강한 뉴런의 활성화가 근처 다른 뉴런의 활동을 제한한다는 것에서 영감을 얻었습니다.
ReLU 결과 값을 Normalization 하여 일반화 된 모델을 만들기 위해 Local Response Normalization (LRN) 을 사용하였습니다. 실제로 CIFAR 10 data로 LRN이 없을 때는 error rate가 13%였고, LRN 을 사용하여 11%로 error rate를 감소 시켰습니다.
4. Overlapping pooiling 사용
기존의 CNN 에서는 kernel을 사용할때 overlap 하는 연산을 사용하지 않았습니다. 즉 stride가 kernel size 보다 커서 kernel의 중복이 없었습니다. 다시 말하면 Pooling 할때 겹쳐서 하지 않았습니다.
하지만 Overlapping pooling은 , Pooling 윈도우 크기를 Stride 크기보다 크게 사용하여 , Overfitting 을 막으려 하였습니다.
실제 CIFAR 10 data에서 0.3~0.4%의 개선 효과가 있었습니다.
Alexnet의 구조

위의 그림과 같이 AlexNet은 Input 이미지는 227 X 227 크기의 RGB 이미지 이며 , 5개의 Convolution layer와 3개의 FC layer로 구성되어 있습니다.
Conv 3 , Conv4 는 Pooling이나 Normalization 없이 진행되었습니다.
과적합(Overfitting) 방지를 위한 노력
Alexnet에서 사용된 파라미터의 수는 6000만 개입니다. 120만개의 이미지로 학습을 하면 과적합이 발생할수 있기 때문에 과적합 방지에 사용된 기법은 아래의 2가지 입니다.
1. Data Augmentation
많은 데이터를 학습할수록 우리는 일반적인 결과를 얻을수 있습니다. Data augmentation은 학습할 데이터를 임의로 늘리는 것인데 , 아래 2가지는 Alexnet에서 사용된 기법으로 simple 하면서도 쉬운방법으로 흔히 사용되는 기법입니다.
1) 이미지 좌우반전 : 256 X 256 사이즈의 이미지를 224 X 224 사이즈의 이미지로 추출하여 좌우를 바꿔 생성합니다.
이 방법을 이용하면 1 장의 이미지로 2024장의 이미지로 늘릴수 있습니다.
2) RGB 채널 변경
원래의 RBG 채널이미지에 각각 채널에 아래 값을 더해주어 이미지의 수를 늘렸습니다.

p 와 람다는 eigen 벡터와 eigen value 이고, 알파는 랜덤 변수입니다.
2. Dropout
특정 확률로 일부 뉴런을 활성하 시키지 않고, Feedforward 와 역전파에 참여시키 않는 기법으로 어찌보면 , 매번 학습할때 마다 Hidden layer에서 참여되는 node가 달라지기 때문에 다른 구조의 신경망이라 할수 있습니다.
이것을 통해 오버피팅을 방지하였습니다.
기타 사항
논문의 뒷부분에 learning 파라미터등에 대해 설명해두었습니다.
128개의 batch 사이즈를 가진 SGD를 사용하였고, 모멘턴값 , Weight decay 등 학습에 사용된 파라미터 세부사항에 대해 언급하였습니다. 가중치 초기화에는 zero-mean 가우시안을 사용하고 , 모든 레이어에 동일한 learning rate를 사용하였다고 언급되어 있습니다. 자세한것은 논문을 보시면 됩니다.
'Deep Learning' 카테고리의 다른 글
| Overfitting (과적합)을 막는 방법- Regularization(정규화) (0) | 2022.07.20 |
|---|---|
| 신경망을 깊게 쌓아보자 !! VGG Net (VERY DEEP CONVOLUTIONALNETWORKSFORLARGE-SCALEIMAGERECOGNITION 논문 리뷰) (0) | 2022.07.12 |
| ResNet 이란 무엇인가?(논문리뷰 포함 : Deep Residual Learning for Image Recognition) (0) | 2022.06.30 |
| CNN 이란 무엇인가? (0) | 2022.06.28 |
| 딥러닝이란 무엇인가? (0) | 2022.06.22 |



