VGGNet의 논문인 VERY DEEP CONVOLUTIONALNETWORKSFORLARGE-SCALEIMAGERECOGNITION 에서는 3 X 3 Convolution filter만을 사용해서 CNN의 모델 layer를 깊게 쌓아 , large- scale image에서의 정확도를 높였다라고 요약할수 있습니다.
1. ConvNet configuration
1) Architecture
- Input image 는 224 x 224 를 사용하였습니다.
- Input image의 전처리로는 각각의 픽셀에서 mean RGB 값을 뺴는것만 하였습니다.
- Convolution Filter : 필터중 가장 작은 3 x 3 Conv.Filter 만 사용하였습니다. (Stride 는 1 사용)
- Pooling Layer : 5개의 Max pooling layer를 사용하고 Conv.Layer 뒤에서 사용하였습니다. (Max Pooling layer는 stride 2 와 2 x 2 픽셀의 윈도우 사이즈 입니다.)
- FC(Fully connected) Layer : 총 3개를 사용하고 처음 2개는 4096 개의 channel로 구성되고 마지막 3번째는 1000개의 채널로 구성되었습니다.)
- Softmax를 사용해서 1000개의 Image class를 구별하였습니다.
- 모든 Layer는 ReLU activation function 을 사용하였습니다.
- AlexNet에서 사용되었던 LRN 같은 정규화는 사용하지 않았습니다.. (메모리와 시간만 잡아먹는다고 적혀있습니다.)
2) Configuration
아래와 같이 Layer의 깊이를 조금씩 다르게 하여 Configuration 을 연구를 하였다고 합니다. 기본적으로 1)의 architecture를 따르며 깊이가 조금씩 다릅니다.

3)Discussion
저자는 3 x 3 Conv. filter 2개 사용하는것이 5 x 5 Conv.filter 1개를 사용하는 것과 비슷하다고 이야기 하고 있습니다.
또한 3 x 3 Conv.filter 3개 사용하는것과 7 x 7 Conv.filter 1개 사용하는것에 대해 비교하는데 , Con.filter 통과후 Relu라는 Activation function 을 사용하기 때문에 3 x 3 이 7 x 7 보다 Activation function (ReLU) 을 많이 통과하기 때문에 Non-Linear 한 문제를 잘 풀수 있다고 합니다.
2. Classification Framework
VGGNet 이 어떻게 학습(Training)되고 평가(Evaluation) 되는지에 대해 설명하였습니다.
1) Training
학습에 사용된 hyper parameter 값에 대해 설명하였습니다. (Multinomial logistic regression 사용)
- Batch size : 256
- Optimizer : Momentum ( 0.9 )
- Regularization : L2 norm
- Learning rate : 10 ^-2
Alex Net 보다 Layer를 깊게 쌓고, 파라미터수도 많아도 더 적은 epochs를 사용했다고 합니다. 왜냐면 implicit regularisation 과 pre-initialisation of certain layers 라고 합니다.
implicit regularisation 은 3 x 3 conv.filter를 사용함으로써 파라미터수를 줄일수 있다는것이고, pre-initialisation of certain layer는 위의 Configuration 파트에서 A라는 구조의 VGGNet을 구성하고 학습된 모델을 B,C,D,E 에 사용했다는 점입니다.
Training image size : 이미지의 특성상 여러사이즈의 이미지가 존재합니다.
그래서 이미지의 가로 x 세로 중 작은 부분을 isotropically-rescaled training image 을 이용해 비율을 유지해 이미지를 줄이고 랜덤하게 Crop을 합니다. 이때 작은부분을 S라고 합니다.
S를 setting 하는 방법은 2가지가 있습니다.
하나는 S를 256 혹은 384로 고정하는 single-scale training 방식이 있고, 또하나는 S를 256~512 사이에서 랜덤하게 샘플링 하는 multi-scale training 방식이 있습니다. 이것을 scale jittering 이라고 합니다.
2) Testing
Tesing image size : test 에 사용되는 image의 값을 Q라고 명시하고 , training 에 사용된 S와 동일할 필요가 없다고 합니다.
1번째 FC layer를 7x7 conv.layer 로 변경하고 , 뒤의 2개 FC layer를 1 x 1 conv.layer로 변경하였습니다.
Classification Experiments
실험결과에 대해 언급하였는데 , 데이터셋은 ILSVRC-2012를 사용하였습니다.
Validation set을 Test set으로 사용하였습니다.
1) Single scale evaluation
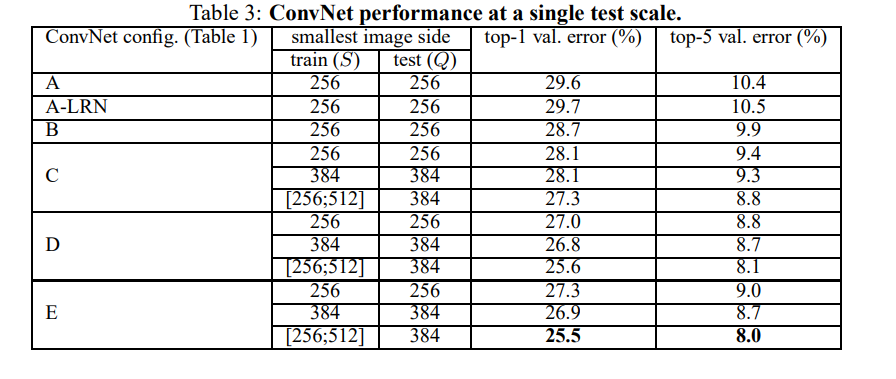
S=Q로 test 이미지 사이즈가 고정됨음 의미합니다. A 나 A-LRN 이 별차이가 없어서 B, C, D, E에는 LRN을 사용하지 않았습니다.
C , D , E에서 사용된 scale - jittering 이 ([256;512]) single-scaled ( 256 혹은 384로 고정)보다 좋은 결과가 있음을 보여주었습니다.
2) Multi-scale evaluation
test(Q)이미지를 여러사이즈로 변경하여 실험하였습니다. Single -scale evaluation 과 마찬가지로 C, D, E에서 사용된 scale - jittering 가 좋은결과를 보여주었습니다.

결론은 VGG Net 으로 ILSVRC 2014 에서 좋은 결과(2등)를 얻었다고 합니다.

'Deep Learning' 카테고리의 다른 글
| Overfitting (과적합)을 막는 방법- Regularization(정규화) (0) | 2022.07.20 |
|---|---|
| CNN의 원조 계승자 : AlexNet (논문 리뷰포함 : ImageNet Classification with Deep Convolutional Neural Networks) (0) | 2022.07.06 |
| ResNet 이란 무엇인가?(논문리뷰 포함 : Deep Residual Learning for Image Recognition) (0) | 2022.06.30 |
| CNN 이란 무엇인가? (0) | 2022.06.28 |
| 딥러닝이란 무엇인가? (0) | 2022.06.22 |



