Overfitting ( 과적합) 을 방지하기 위해서 여러가지 기법들이 사용되고 있습니다. 이것을 통상적으로 정규화한다 하고 Regularization 이라고 합니다.
우선 Overfitting( 과적합) 에 대해 간단히 말씀드리겠습니다. 데이터가 주어지고 학습모델을 그 데이터에 너무 딱 맞게 학습한것을 Overfitting (과적합) 이라 합니다. 모델이 Overfitting 이 되면 새로운 데이터가 들어오면 예측결과가 달라질수 있습니다. 그래서 모델을 학습할때 어느정도 일반화 된 모델을 설계해야합니다.
그러면 Overfittimg 을 피하기 위하여 사용되는 정규화기법에는 무엇이 있을까요? 정말 많은 정규화 방법이 있는데 이중 Dropout , Weight Decay 에 대해서 살펴 보도록 하겠습니다.
Dropout
신경망 레이어 중간에 Noise를 주어 학습데이터를 조금씩 다른 모델로 학습하자는 컨셉입니다.
그러면 Noise를 어떻게 줄수 있을까요? Dropout 은 Layer의 Node를 random 하게 빼고 이 random 확률을 Parameter로 지정하여 내가 임의로 설정할수 있게 하였습니다. (여기서 Node는 신경망의 Hidden Layer를 말합니다.)

학습(Training)을 할때에는 확률 p 에 따라 node를 turn on / off 할수 있지만 ,
추론(Testing) 을 할때에는 모든 Node를 사용하고, 그렇게 되면 입력이 학습때 보다 1/P 배 많이 들어오게 됩니다. 그래서 p를 W에 곱해서 이를 상쇄시킵니다.
즉 다시 말씀드리면 dropout은 학습(Training)에서만 사용됩니다.
그렇다면 dropout 에 사용되는 확률 p는 어떤값을 사용하면 좋을까요?

위의 그림은 논문(Dropout: A Simple Way to Prevent Neural Networks from Overfitting)에 나와있는 p값을 조정하면서 실험한 내용이고 , 요약하자면 0.5를 써라고 합니다. 그냥 0.5 쓰시면 됩니다 ^^
Weight Decay
신경망의 노드와 노드의 관계의 강도는 W가 클수록 커지는데 , Weight Decay는 노드 간관계의 총량을 제한하여 쓸데없는 관계를 맺을수 없게 만듭니다.
위에서 말한 노드와 노드의 관계의 강도라는 말은 Loss funtion 이 작아지도록 W를 구하다 보면 특정 가중치 값들이 커지면서 Overfitting 이 발생할수 있다는것을 말합니다. 즉 너무 Loss funtion 을 작게한다고 노력하지말고 어느정도 느슨하게 만들어 일반화 된 모델을 구하자는 노력의 일환이라고 보면 됩니다.
즉 학습된 모델의 복잡도를 줄이기 위해 weight 가 커지는 것을 막을수 있습니다. 이것을 어떻게 할까요? 일반적으로 Loss function 에 weight가 커질 경우에 대해 패널티 항목을 집어 넣어 weight가 커지는 것을 막을 수 있습니다.
대표적으로 사용되는 기법은 L1-norm , L2-norm 이 있습니다.
우선 L1-norm과 L2-norm 의 공식을 보면 Loss funtion term 과 페널티 term이 있습니다. 즉 목적은 Loss function term이 작아질 수록 페널티 term이 커지게 하는 컨셉입니다. 그래서 적절한 람다값(페널티 term 값의 계수)을 찾아 두 term 사이에 균형을 잘 조절해주어야합니다.
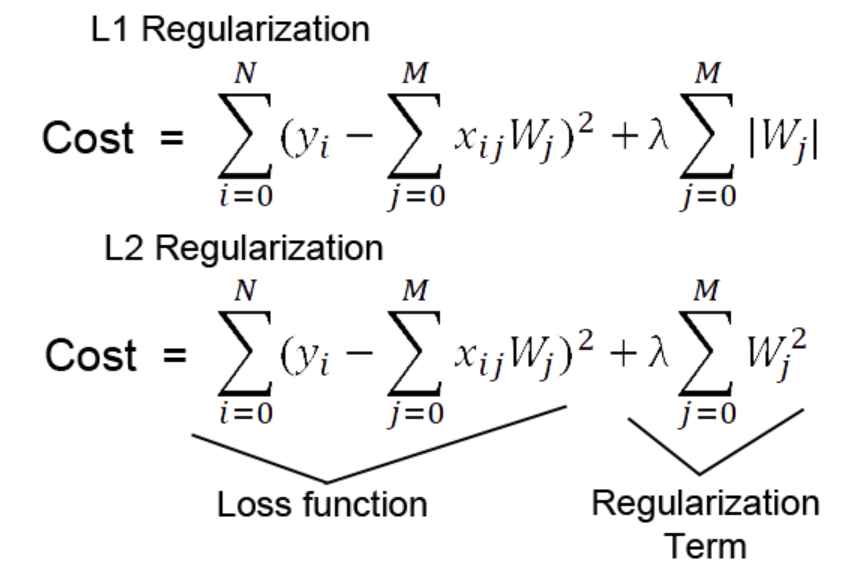
L1 -norm 은 L2-norm 보다 outlier 에 대해 강건하다고 말할수 있습니다. 왜냐면 L2는 제곱항을 가지고 있어 outlier가 들어오면 값이 급격히 증가하지만 , L1의 경우 절대값을 더해주기때문에 outlier에 대해 선형적인 증가만 하게 됩니다.
'Deep Learning' 카테고리의 다른 글
| 신경망을 깊게 쌓아보자 !! VGG Net (VERY DEEP CONVOLUTIONALNETWORKSFORLARGE-SCALEIMAGERECOGNITION 논문 리뷰) (0) | 2022.07.12 |
|---|---|
| CNN의 원조 계승자 : AlexNet (논문 리뷰포함 : ImageNet Classification with Deep Convolutional Neural Networks) (0) | 2022.07.06 |
| ResNet 이란 무엇인가?(논문리뷰 포함 : Deep Residual Learning for Image Recognition) (0) | 2022.06.30 |
| CNN 이란 무엇인가? (0) | 2022.06.28 |
| 딥러닝이란 무엇인가? (0) | 2022.06.22 |



